Deploy Your Streamlit App with Python, Docker, Nginx, and Cloudflare
Have you ever heard of an open-source project called Streamlit? Let me tell you – Streamlit is truly lit 🔥. It allows you to turn simple Python scripts into shareable web apps in just minutes. Yes, really – minutes! Here’s all the code you need to create a basic app:
import streamlit as st
st.write("Hello, World!")
One of the coolest features of Streamlit is its ability to deploy your app to their Community Cloud – for free! The only trade-off is that your app becomes public by default, unless you choose to share it privately. You can explore what the community has been building in their Gallery.
Now, this all sounds amazing, but what if I don’t want everything to be public? What if I prefer not to use their domain name to publish my apps? Believe me, I’ve looked into configuring a DNS. I even found this article on deploying with Cloudflare Workers. But honestly? That’s not for me. I’d much rather self-host! I already have some ideas on how to make it happen, and if it doesn’t go as planned, it’ll still be a great learning experience!
I’m also trying something different. This blog post will be an in-depth journal of how I built the repository! That’s why it’s over 5700 words…
🐍 Setting Up Two Basic Streamlit Apps
The first step is to create an apps directory to house your Streamlit applications. Each app (app_1 and app_2) will have its own requirements.txt file, treating each as an independent environment. This way, each app can exist in its “own little world.”
apps/
├── app_1/
│ ├── app_1.py
│ ├── README.md
│ └── requirements.txt
└── app_2/
├── app_2.py
├── README.md
└── requirements.txt
README.md
We’ll use Python’s Virtual Environments to isolate dependencies for each app. For now, the requirements.txt file is minimal:
streamlit==1.41.*
I’ve pinned the streamlit dependency at the minor version level, allowing updates for any patch releases.
🐳 A Basic Docker Setup to Get Going
⚙ The Main Docker Process
The next step is configuring a basic Docker container. We’ll use VS Code’s Dev Containers to connect to the container. For this, the container must be running to allow connections.
By default, a Docker container runs a single process, and when this process completes, the container stops. Let’s demonstrate this with the hello-world image:
docker run hello-world
This outputs:
Unable to find image 'hello-world:latest' locally
latest: Pulling from library/hello-world
c1ec31eb5944: Pull complete
Digest: sha256:1b7a37f2a0e26e55ba2916e0c53bfbe60d9bd43e390e31aacd25cb3581ed74e6
Status: Downloaded newer image for hello-world:latest
Hello from Docker!
This message shows that your installation appears to be working correctly.
To generate this message, Docker took the following steps:
1. The Docker client contacted the Docker daemon.
2. The Docker daemon pulled the "hello-world" image from the Docker Hub.
(amd64)
3. The Docker daemon created a new container from that image which runs the
executable that produces the output you are currently reading.
4. The Docker daemon streamed that output to the Docker client, which sent it
to your terminal.
To try something more ambitious, you can run an Ubuntu container with:
$ docker run -it ubuntu bash
Share images, automate workflows, and more with a free Docker ID:
https://hub.docker.com/
For more examples and ideas, visit:
https://docs.docker.com/get-started/
Running docker ps -a will list all containers, including those that have exited:
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
c6fdd29065fc hello-world "/hello" 2 minutes ago Exited (0) 2 minutes ago boring_mclean
In this case, the main process inside the hello-world container simply prints a message to the screen and then exits.
🔁 Keeping the Docker Container Running
A lightweight way to keep a container running is to use:
tail -f /dev/null
This command creates an infinite loop where tail continuously attempts to read from /dev/null. Since /dev/null is always empty, tail remains in a waiting state.
To test this, run:
docker run -d --name tail-demo alpine tail -f /dev/null
If your terminal doesn’t register the last “l” correctly, an alternative is:
docker run -d --name tail-demo alpine sh -c "tail -f /dev/null"
Now, running docker ps -a should show:
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
2813c19cc028 alpine "sh -c 'tail -f /dev…" 6 seconds ago Up 5 seconds tail-demo
c6fdd29065fc hello-world "/hello" 20 minutes ago Exited (0) 20 minutes ago boring_mclean
🛑 Stopping and Cleaning Up Containers
To stop the tail-demo container, use:
docker stop --time=10 tail-demo
This sends a SIGTERM signal, allowing the container to shut down gracefully within the specified 10-second grace period. If the container does not stop in time, Docker will send a SIGKILL. You can adjust the grace period using the --time flag.
To remove the containers, use either the name or container ID:
docker rm tail-demo
docker rm c6fdd29065fc
🙇♂️ Supervisor, Dockerfile, and Makefile
The Supervisor program is an excellent tool for managing multiple running processes in a Linux environment. By integrating it into your container, you can effectively manage multiple services within the container itself.
Using Supervisor in a container allows you to manage more than one service in a seamless and organized way. For example, Supervisor is a process control system for UNIX-like operating systems that helps manage long-running processes. Here’s an example of a Dockerfile utilizing Supervisor:
FROM ubuntu:22.04
ARG APP_ENV
RUN apt-get update && apt-get install -y supervisor
WORKDIR /self-hosted-streamlit-apps
COPY . /self-hosted-streamlit-apps
COPY supervisord.conf /etc/supervisor/conf.d/
CMD ["supervisord", "-c", "/etc/supervisor/supervisord.conf"]
Supervisor provides robust control and better process management, making it easy to monitor and handle processes. Even if a process inside the container needs restarting, the main process (supervisord) will continue running as PID 1, ensuring the container remains operational.
This approach is ideal for running more complex workloads inside a container.
To start, we can create a simple supervisord.conf file with a basic configuration:
[supervisord]
nodaemon=true
[program:tail]
command=tail -f /dev/null
autostart=true
This minimal configuration helps us get started. Next, let’s build our image using docker build. The following command includes an APP_ENV build argument to specify the type of container being built:
docker build --build-arg APP_ENV=production -t self-hosted-streamlit-prod .
If this is your first time pulling the ubuntu image, it might take some time, so grab a coffee while you wait. Once the image is built, you can run it using:
docker run -d --name streamlit --env-file .env self-hosted-streamlit-prod
You may notice the --env-file argument. This allows you to include API keys or other sensitive information later. To prevent accidental leaks, add .env to both .gitignore and .dockerignore files:
.env
apps/*/.env
Where the contents of our .env file will have the following:
HELLO="WORLD"
Let’s confirm everything is running with docker ps -a:
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
c6fda0d60b6d self-hosted-streamlit-prod "/usr/bin/supervisor…" 17 seconds ago Up 16 seconds streamlit
Everything looks good! You can now enter the container in interactive mode using:
docker exec -it streamlit sh
Once inside, verify that your environment variables are accessible, e.g., echo $HELLO should return "WORLD". Running ls -la will also confirm that .env wasn’t copied into the container.
Remembering all these commands can be tedious. To simplify, we can use scoop to install make:
scoop install make
This allows us to define a Makefile for easier management:
IMAGE_NAME_PROD=self-hosted-streamlit-prod
build-prod:
docker build --build-arg APP_ENV=production -t $(IMAGE_NAME_PROD) .
run-prod:
docker run -d --name $(CONTAINER_NAME_PROD) --env-file .env $(IMAGE_NAME_PROD)
exec-prod:
docker exec -it $(CONTAINER_NAME_PROD) sh
start-prod:
docker start $(CONTAINER_NAME_PROD)
stop-prod:
docker stop $(CONTAINER_NAME_PROD)
remove-prod:
docker rm $(CONTAINER_NAME_PROD)
rebuild-prod: stop-prod remove-prod build-prod run-prod
With this setup, you can easily manage the lifecycle of your container:
- Build the image:
make build-prod - Run the container:
make run-prod - Access the container shell:
make exec-prod - Stop the container:
make stop-prod - Remove the container:
make remove-prod - Rebuild everything:
make rebuild-prod
This approach simplifies container management and can be easily extended for a development environment.
Our directory currently looks like this:
apps/
├── app_1/
│ ├── .env
│ ├── app_1.py
│ ├── README.md
│ └── requirements.txt
└── app_2/
├── .env
├── app_2.py
├── README.md
└── requirements.txt
.dockerignore
.env
.gitignore
Brewfile
Makefile
README.md
supervisord.conf
💪 Creating a better supervisor.conf File
⛏ Setting Up supervisorctl
To fully unlock the capabilities of supervisorctl, we need to configure our supervisor.conf file. The first step is setting up a unix_http_server section. This enables us to manage processes using commands like supervisorctl restart app_1.
supervisorctl communicates with supervisord via XML-RPC over a specified port. For a good chmod reference, this chmod calculator can be handy.
The documentation advises against using the /tmp directory as shown in the examples. Instead, we’ll use the /var directory:
[unix_http_server]
file=/var/run/supervisor.sock
chmod=0700
[supervisorctl]
serverurl=unix:///var/run/supervisor.sock
The supervisorctl section simply points to the socket file. Additionally, we can define global settings for the supervisord process:
[supervisord]
logfile=/var/log/supervisor/supervisord.log
pidfile=/var/run/supervisord.pid
childlogdir=/var/log/supervisor
nodaemon=true
Finally, include this RPC interface setting:
[rpcinterface:supervisor]
supervisor.rpcinterface_factory = supervisor.rpcinterface:make_main_rpcinterface
Per the documentation:
If you don’t need any additional functionality beyond what
supervisorprovides out of the box, this is all you need to configure.
Here’s the complete configuration file:
[unix_http_server]
file=/var/run/supervisor.sock
chmod=0700
[supervisord]
logfile=/var/log/supervisor/supervisord.log
pidfile=/var/run/supervisord.pid
childlogdir=/var/log/supervisor
nodaemon=true
[rpcinterface:supervisor]
supervisor.rpcinterface_factory = supervisor.rpcinterface:make_main_rpcinterface
[supervisorctl]
serverurl=unix:///var/run/supervisor.sock
[program:tail]
command=tail -f /dev/null
autostart=true
autorestart=true
stderr_logfile=/var/log/supervisor/tail.err.log
stdout_logfile=/var/log/supervisor/tail.out.log
🌍 Creating Python Virtual Environments for each app and updating Supervisor
🐳 Revisiting our Dockerfile
Now for the real MVP – Python 🐍! I explored options like installing Python via apt-get, Homebrew, and even building it from source. Ultimately, I decided to use a base image with Python pre-installed. Since my laptop uses Python 3.11, I chose the python:3.11-slim Docker image.
Here’s the updated Dockerfile! I’ll get to the juicy details 🧃
FROM python:3.11-slim
# ====== Environment Variables ======
ENV APP_ROOT=/self-hosted-streamlit-apps
# ====== Arguments ======
ARG DEBIAN_FRONTEND=noninteractive
# ====== Install Dependencies ======
RUN apt-get update && apt-get install -y \
build-essential \
curl \
file \
git \
supervisor \
nginx \
&& apt-get clean \
&& rm -rf /var/lib/apt/lists/*
# ====== Working Directory Setup ======
WORKDIR $APP_ROOT
COPY . .
RUN mkdir -p /var/log/supervisor
# ====== Build Scripts ======
RUN python build.py -dH && \
cp supervisord.conf /etc/supervisor/supervisord.conf
# ====== Entrypoint and Healthcheck ======
HEALTHCHECK --interval=5m --timeout=3s --retries=3 \
CMD python healthcheck.py || exit 1
CMD ["/usr/bin/supervisord", "-n", "-c", "/etc/supervisor/supervisord.conf"]
After revisiting the documentation, I refined the setup with a few best practices:
ENV: Sets the root path for scripts requiring it.ARG: Helps during installation (DEBIAN_FRONTEND=noninteractive). The docs mentioned that it’s better to add it as a buildARGinstead of an environmentENVHEALTHCHECK: Ensures the container is functioning properly, adding ahealthystatus. When a container has a healthcheck specified, it has a health status in addition to its normal status. This status is initiallystarting. Whenever a health check passes, it becomeshealthy(whatever state it was previously in). After a certain number of consecutive failures, it becomesunhealthy.- I’ve also removed the
COPYinstruction to copy thesupervisord.conffile. TheCOPYcreates a layer and caches it. This is a problem when you want to run scripts likebuild.pywhich modifies thesupervisord.conffile - I’ve also added
nginxto the installation. More on that later!
I also removed the APP_ENV ARG since I wanted the variable to persist across environments. I added a -e APP_ENV=PROD and -e APP_ENV=DEV argument after the --env-file arguments in the run-* Make commands
🐍 Python Scripts: build.py and healthcheck.py
You’re probably wondering what build.py and healthcheck.py are for. Well… I know bash scripting was designed for tasks like these. I could spend days learning it, or I could use an LLM (which might turn it into a mysterious black box of unicorns), but instead, I decided to write the build and health check logic in Python! It’s a language I’m comfortable with, and the container is already set up for it.
Here’s a simple starting point for healthcheck.py:
import sys
if __name__ == "__main__":
sys.exit(0) # Healthy!
I’ll revisit this file later since I don’t yet know what would make it truly “healthy.” After running make rebuild-prod, I can confirm it works:
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
fa4ae30d7e94 self-hosted-streamlit-prod "/usr/bin/supervisor…" About a minute ago Up About a minute (healthy) streamlit-prod
Cool 😎!
As for the build.py file, its primary job is to create a virtual environment for each Streamlit app and append the necessary settings to the supervisord.conf file. I’m planning to add two arguments to this script:
-d,--deploy: A flag that must be explicitly set. When enabled, it modifies the configuration files.-H,--hard: Removes the existing virtual environments (.venv) and creates new ones.
I won’t go into all the nitty-gritty details, but let’s review the key functions. The script includes a main function, which orchestrates everything:
def main(args: argparse.Namespace) -> None:
if not os.path.exists(APPS_ROOT_PATH):
_e: str = f"Could not find {APPS_ROOT_PATH}"
logger.critical(_e)
raise FileNotFoundError(_e)
for app_folder_name in os.listdir(APPS_ROOT_PATH):
app_folder_path: str = os.path.join(APPS_ROOT_PATH, app_folder_name)
logger.info(f"Building {app_folder_name}")
# =========== // STEP 1: LOAD SETUP FILE // ===========
logger.info(f"[{app_folder_name}] Loading settings...")
setup: Setup = load_setup(app_folder_path)
# =========== // STEP 2: CREATE VENV AND INSTALL PACKAGES // ===========
logger.info(f"[{app_folder_name}] Creating venv and installing Python dependencies...")
create_venv_and_install(
setup=setup,
args=args
)
# =========== // STEP 3: UPDATE SUPERVISOR CONF // ===========
if args.deploy:
logger.info(f"[{app_folder_name}] Updating Supervisor configuration...")
backup_file(SUPERVISOR_CONF_PATH)
update_supervisor_conf(
setup=setup
)
else:
logger.info("Skipping Supervisor update")
# =========== // STEP 4: UPDATE NGINX CONF // ===========
if args.deploy:
logger.info(f"[{app_folder_name}] Updating Nginx configuration...")
update_nginx_conf(
setup=setup
)
else:
logger.info("Skipping Nginx update")
The main function performs the following steps for each folder in the ./apps directory:
- Loads the settings file.
- Creates a virtual environment and installs the required packages.
- Updates the Supervisor configuration (if the
--deployflag is set). - Updates the Nginx configuration (also dependent on the
--deployflag).
There’s still some work to do, particularly with setting up the Nginx configuration, but this is a solid starting point!
🔍 (1) Loading a Settings File
After my morning run, I had a great idea: why not use Python’s built-in tomllib package to manage each app’s settings? Each app will now have its own setup.toml file in its root directory. Here’s an example of the setup.toml file for app_1:
title = "App 1"
[owner]
name = "Johan"
[streamlit]
port = 8001
base_path = "/app-1"
entry_file = "app_1.py"
Thanks, TOML! The load_setup function reads this file and initializes a dataclass to validate the settings easily:
@dataclass
class Owner:
name: str = ""
@dataclass
class Streamlit:
port: int
base_path: str
entry_file: str
@dataclass
class Setup:
title: str = ""
owner: Owner = None
streamlit: Streamlit = None
app_folder_path: str = ""
pip_path: str = ""
python_path: str = ""
def load_setup(
app_folder_path: str,
setup_name: str = SETUP_NAME
) -> Setup:
with open(os.path.join(app_folder_path, setup_name), "rb") as f:
data = tomllib.load(f)
return Setup(
title=data['title'],
owner=Owner(**data['owner']),
streamlit=Streamlit(**data['streamlit']),
app_folder_path=app_folder_path
)
Using dataclasses has several advantages, but the biggest one for me is the autocomplete feature. When I type setup.streamlit.port, I get suggestions all the way! It also helps me see all available options as I type. I’m a huge fan.
🔍 (2) Creating a Virtual Environment and Installing Packages
The create_venv_and_install function handles the following:
def create_venv_and_install(
setup: Setup,
args: argparse.Namespace
) -> None:
# =========== // STEP 1: SET PYTHON AND PIP PATHS // ===========
venv_path: str = os.path.join(setup.app_folder_path, VENV_NAME)
if sys.platform == "win32":
pip_path = os.path.join(venv_path, "Scripts", "pip")
python_path = os.path.join(venv_path, "Scripts", "python")
else:
pip_path = os.path.join(venv_path, "bin", "pip")
python_path = os.path.join(venv_path, "bin", "python")
# Store these paths for later use
setup.pip_path = pip_path
setup.python_path = python_path
# =========== // STEP 2: HANDLE HARD RESET // ===========
if args.hard_reset and os.path.exists(venv_path):
logger.info(f"[{setup.title}] Removing {venv_path}")
shutil.rmtree(venv_path)
# =========== // STEP 3: CREATE AND INSTALL // ===========
if not os.path.exists(venv_path):
# ==========> STEP 3.1: CREATE THE VIRTUAL ENVIRONMENT
logger.debug(f"[{setup.title}] Creating virtual environment")
run_command(
[
PY,
"-m",
"venv",
venv_path
]
)
# ==========> STEP 3.2: INSTALL DEPENDENCIES
logger.debug(f"[{setup.title}] Installing requirements")
run_command(
[
pip_path,
"install",
"-r",
"requirements.txt"
],
cwd=setup.app_folder_path
)
else:
logger.warning(f"[{setup.title}] {VENV_NAME} already exists. Use `--hard` to remove it.")
This function can be broken down into three main steps:
-
Set the Python and pip paths
Based on the platform, thepython_pathandpip_pathare determined. For Windows, they’re located in theScriptsdirectory; for Linux and similar systems (like containers), they’re in thebindirectory. These full paths are saved for later use. -
Handle a hard reset
If the--hardargument is passed, any existing virtual environment is removed. -
Create the virtual environment and install dependencies
- Step 3.1: Create the virtual environment using
python -m venv .venv. - Step 3.2: Install dependencies from the
requirements.txtfile usingpip install -r requirements.txt.
- Step 3.1: Create the virtual environment using
The run_command function is a simple wrapper around subprocess.run to handle system commands:
def run_command(
command: List[str],
cwd: Optional[str] = None
) -> None:
result: subprocess.CompletedProcess = subprocess.run(
command,
cwd=cwd,
text=True
)
result.check_returncode()
This wrapper ensures that commands run in the specified directory (if provided) and raises an error if the command fails.
🔍 (3) Updating the Supervisor Configuration
The update_supervisor_conf function is executed only when the args.deploy argument is passed to the script. Here’s how the function is defined:
def update_supervisor_conf(
setup: Setup
) -> None:
with open(SUPERVISOR_CONF_PATH, "a") as f:
f.write("\n")
f.write(
create_supervisor_program_str(
app_name=to_snake_case(str(setup.title)),
python_path=setup.python_path,
app_folder_path=setup.app_folder_path,
app_python_file=setup.streamlit.entry_file,
server_base_path=setup.streamlit.base_path,
server_port=setup.streamlit.port
)
)
This function takes the properties of a Setup instance and appends the output of create_supervisor_program_str to the supervisord.conf file, referenced here as SUPERVISOR_CONF_PATH.
The create_supervisor_program_str function formats the input arguments into a Supervisor-compatible configuration string. Here’s how it looks:
def create_supervisor_program_str(
*,
app_name: str,
python_path: str,
app_python_file: str,
app_folder_path: str,
server_port: int,
server_base_path: str
) -> str:
return """[program:{app_name}]
command={python_path} -m streamlit run {app_python_file} --server.port={server_port} --server.baseUrlPath={server_base_path}
directory={app_folder_path}
autostart=true
autorestart=true
stderr_logfile=/var/log/supervisor/{app_name}.err.log
stdout_logfile=/var/log/supervisor/{app_name}.out.log
""".format(
app_name=app_name,
python_path=python_path,
app_python_file=app_python_file,
app_folder_path=app_folder_path,
server_port=server_port,
server_base_path=server_base_path
)
Notice the use of the * argument notation to enforce keyword arguments. Although an f-string could have been used here, I decided to revisit .format() for nostalgic purposes! The formatted output for an app might look like this:
[program:app_1]
command=/self-hosted-streamlit-apps/apps/app_1/.venv/bin/python -m streamlit run app_1.py --server.port=8001 --server.baseUrlPath=/app-1
directory=/self-hosted-streamlit-apps/apps/app_1
autostart=true
autorestart=true
stderr_logfile=/var/log/supervisor/app_1.err.log
stdout_logfile=/var/log/supervisor/app_1.out.log
Testing the Configuration
Before diving into NGINX, let’s test this setup. First, add the following commands to your Makefile:
run-prod-80:
docker run -d --name $(CONTAINER_NAME_PROD) --env-file .env -e APP_ENV=PROD -p 80:80 $(IMAGE_NAME_PROD)
rebuild-prod-80: stop-prod remove-prod build-prod run-prod-80
These commands allow you to create a container and map port 80 on your machine to the container. Now, run make run-prod-80 to start the container. The output of docker ps -a should confirm the port mapping:
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
1d2dc7b470b8 self-hosted-streamlit-prod "/usr/bin/supervisor…" 7 seconds ago Up 6 seconds (healthy) 0.0.0.0:80->80/tcp streamlit-prod
The port mapping looks correct! Next, use make exec-prod to access the container and verify that everything is running. Executing supervisorctl status inside the container should return:
app_1 RUNNING pid 7, uptime 0:00:39
app_2 RUNNING pid 8, uptime 0:00:39
tail RUNNING pid 9, uptime 0:00:39
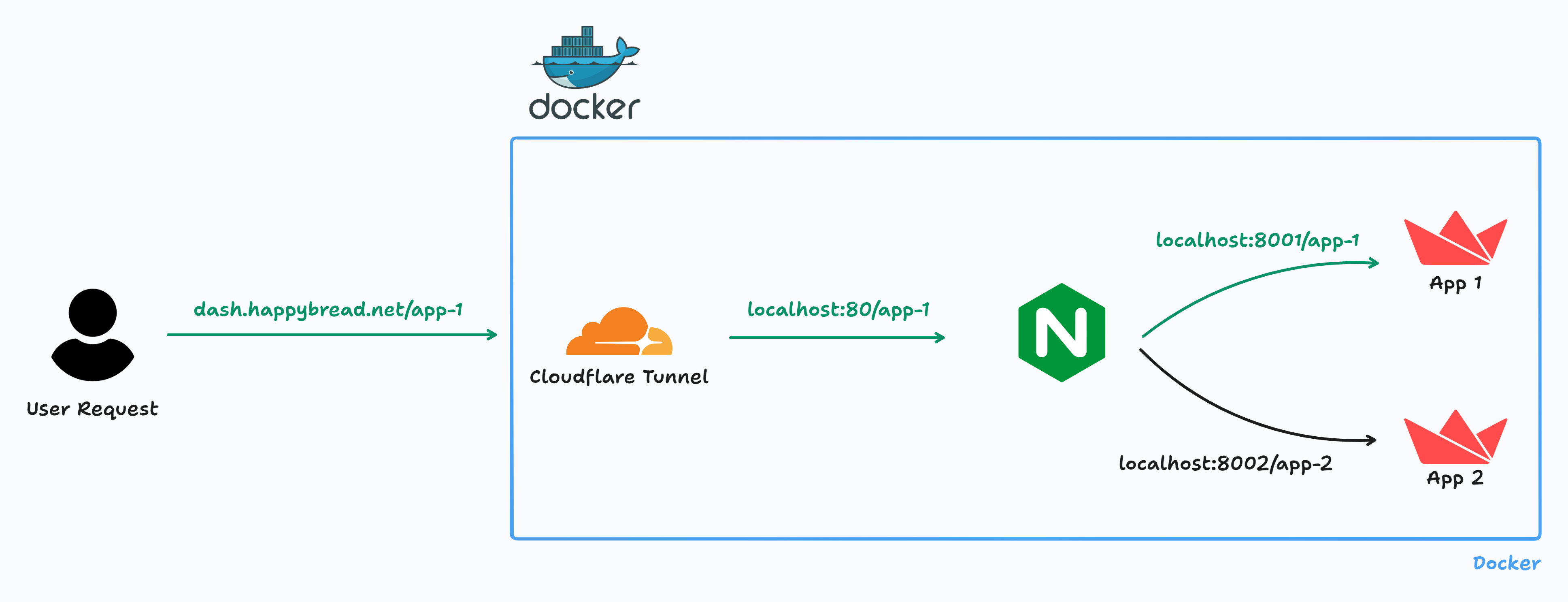
It’s working as expected! Now, open http://localhost:80/app-1 in your browser, and voilà:
🎉🥳🎉 Success! After all that hard work, it’s incredibly satisfying to see everything come together!
🔍 (3) Updating the NGINX Configuration
I’ll be honest—I’m still relatively new to NGINX, so this was a fantastic opportunity to deepen my understanding! The goal here is to use build.py to generate an nginx.conf file and copy it to /etc/nginx/sites-available/default. The updated Dockerfile now includes:
RUN python build.py -dH && \
cp supervisord.conf /etc/supervisor/supervisord.conf && \
cp nginx.conf /etc/nginx/sites-available/default && \
ln -sf /etc/nginx/sites-available/default /etc/nginx/sites-enabled/default
While setting this up, I ran into a similar issue as described in this DigitalOcean forum post. Adding the symlink above resolved it. Reading through the Streamlit Forum, I found the following NGINX configuration suggested by users:
server {
server_name website.com;
location / {
proxy_pass http://127.0.0.1:8501/;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "upgrade";
}
location /_stcore/stream {
proxy_pass http://127.0.0.1:8501/_stcore/stream;
proxy_http_version 1.1;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header Host $host;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "upgrade";
proxy_read_timeout 86400;
}
}
Since I use custom base paths for each app, I modified the configuration as follows:
location /app-1/ {
proxy_pass http://127.0.0.1:8001/app-1/;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "upgrade";
}
location /app-1/_stcore/stream {
proxy_pass http://127.0.0.1:8001/app-1/_stcore/stream;
proxy_http_version 1.1;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header Host $host;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "upgrade";
proxy_read_timeout 86400;
}
One critical note: always include the trailing slash in proxy_pass. It took me three cups of coffee to figure that out! ☕☕☕
For simplicity, I left the other NGINX defaults unchanged. The main idea is to have the script generate the initial nginx.conf file with the first app’s configuration:
return f"""
server {{
listen 80;
server_name localhost;
# Streamlit apps
{locations}
# Default location block
location / {{
return 404;
}}
}}
"""
To add more apps later, the script replaces the # Default location block comment with the next app’s configuration, then re-adds the comment:
new_config = existing_config.replace(
" # Default location block",
f" {location_block}\n # Default location block"
)
Here’s the implementation of update_nginx_conf:
def update_nginx_conf(
setup: Setup
) -> None:
# First-time file creation
if not os.path.exists(NGINX_CONF_PATH):
logger.info(f"[{setup.title}] Creating new nginx configuration")
with open(NGINX_CONF_PATH, "w") as f:
f.write(create_nginx_config([setup]))
else:
# Update existing configuration
with open(NGINX_CONF_PATH, "r") as f:
existing_config = f.read()
backup_file(NGINX_CONF_PATH)
location_block = create_nginx_location_block(
base_path=setup.streamlit.base_path,
port=setup.streamlit.port
)
if location_block not in existing_config:
new_config = existing_config.replace(
" # Default location block",
f" {location_block}\n # Default location block"
)
with open(NGINX_CONF_PATH, "w") as f:
f.write(new_config)
The initial configuration is generated using create_nginx_config:
def create_nginx_config(
setups: List[Setup]
) -> str:
locations = "\n".join(
create_nginx_location_block(
base_path=setup.streamlit.base_path,
port=setup.streamlit.port
)
for setup in setups
)
return f"""
server {{
listen 80;
server_name localhost;
# Streamlit apps
{locations}
# Default location block
location / {{
return 404;
}}
}}
"""
The create_nginx_location_block function generates the location configuration for each app:
def create_nginx_location_block(
*,
base_path: str,
port: int
) -> str:
# Ensure base_path starts with / and ends with /
if not base_path.startswith('/'):
base_path = '/' + base_path
if not base_path.endswith('/'):
base_path = base_path + '/'
return f"""
location {base_path} {{
proxy_pass http://127.0.0.1:{port}{base_path};
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "upgrade";
}}
location {base_path}_stcore/stream {{
proxy_pass http://127.0.0.1:{port}{base_path}_stcore/stream;
proxy_http_version 1.1;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header Host $host;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "upgrade";
proxy_read_timeout 86400;
}}
"""
After some trial and error, this setup worked perfectly! Now, running make rebuild-prod-80 and navigating to http://localhost/app-1/ displays:
And visiting http://localhost/app-2/ shows:
🎉🥳 Success! Seeing it all come together is so satisfying!
🩺 Configuring Health Checks for the Container
Remember the healthcheck.py file we set aside earlier? It’s time to revisit it. Currently, there are two key checks I want to implement:
- Are all
supervisorprocesses running? - Can I access
http://localhost:80/?
This serves as a solid starting point. I also want the ability to override these health checks for debugging purposes. To achieve this, I’ve added an ENV ALWAYS_HEALTHY=false instruction to the container. This allows the following logic in healthcheck.py:
ALWAYS_HEALTHY: bool = str(os.getenv("ALWAYS_HEALTHY", "false")).lower() == "true"
if ALWAYS_HEALTHY:
logger.info(f"{_p} ALWAYS_HEALTHY is enabled")
sys.exit(0)
If something isn’t healthy, we want to know why! To facilitate this, we’ll set up a log handler to save logs to a file. To prevent the logs from growing indefinitely, we’ll use RotatingFileHandler to manage file rotation. Here’s the configuration:
logger: logging.Logger = logging.getLogger(PROG_NAME)
logger.setLevel(logging.DEBUG)
stdout_handler = logging.StreamHandler(sys.stdout)
stdout_handler.setLevel(logging.DEBUG)
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
stdout_handler.setFormatter(formatter)
logger.addHandler(stdout_handler)
if sys.platform != "win32":
os.makedirs(LOG_DIR, exist_ok=True)
file_handler = RotatingFileHandler(
filename=LOG_FILE,
maxBytes=10 * 1024 * 1024, # 10MB
backupCount=5, # Keep 5 backup files
encoding='utf-8'
)
file_handler.setLevel(logging.DEBUG)
file_handler.setFormatter(formatter)
logger.addHandler(file_handler)
Here’s the entry point for healthcheck.py:
if __name__ == "__main__":
_p: str = "[CHECK]"
logger.info(f"{_p} Starting health check")
# =========== // ALWAYS_HEALTHY // ===========
if ALWAYS_HEALTHY:
logger.info(f"{_p} ALWAYS_HEALTHY is enabled")
sys.exit(0)
# =========== // CHECK SUPERVISOR // ===========
processes: Optional[List[Dict]] = get_supervisor_status()
if not processes:
logger.critical(f"{_p} UNHEALTHY - Unable to fetch supervisorctl status")
sys.exit(1)
if not check_supervisor_all_running(processes):
sys.exit(1)
# =========== // CHECK LINKS // ===========
for url in LINKS_TO_CHECK:
if check_ping(url):
logger.info(f"{_p} {url} is online")
else:
logger.critical(f"{_p} Unable to reach {url}")
sys.exit(1)
# =========== // HEALTHY! // ===========
logger.info(f"{_p} All systems are GO!")
sys.exit(0)
The get_supervisor_status function runs the supervisorctl status command using subprocess.run, similar to how we handled virtual environments in build.py:
def get_supervisor_status() -> Optional[List[Dict]]:
try:
result: subprocess.CompletedProcess = subprocess.run(
['supervisorctl', 'status'],
capture_output=True,
text=True,
check=True
)
processes: List[Dict] = []
for line in result.stdout.split('\n'):
if line.strip():
parts: List[str] = re.split(r'\s+', line.strip(), maxsplit=2)
if len(parts) >= 2:
process: Dict[str, str] = {
'name': parts[0],
'status': parts[1],
'details': parts[2] if len(parts) > 2 else ''
}
processes.append(process)
return processes
except subprocess.CalledProcessError as e:
logger.error(f"Error running supervisorctl: {e}")
logger.error(f"Error output: {e.stderr}")
return None
except FileNotFoundError:
logger.error("supervisorctl command not found. Is Supervisor installed?")
return None
If the result is empty, we immediately flag it as unhealthy. If a list of dictionaries is returned, we pass it to check_supervisor_all_running, which evaluates each process and logs its status:
def check_supervisor_all_running(
processes: List[Dict],
ignore: List[str] = SUPERVISOR_STATUS_IGNORE
) -> bool:
if not processes:
logger.critical("No processes to check")
return False
status: bool = True
for supervisor_process in processes:
if supervisor_process['name'] not in ignore:
if supervisor_process['status'] == 'FATAL':
logger.critical(f"{supervisor_process['name']} - FATAL - {supervisor_process['details']}")
status = False
else:
logger.info(f"{supervisor_process['name']} - {supervisor_process['status']} - {supervisor_process['details']}")
return status
We use a flag to log all unhealthy processes before returning the overall status.
Finally, the check_ping function sends a simple HTTP GET request to verify if critical URLs are reachable:
LINKS_TO_CHECK: List[str] = [
"http://localhost:80/app-1"
]
def check_ping(url: str) -> bool:
try:
response = urllib.request.urlopen(url)
return response.getcode() == 200
except Exception:
return False
When executed, docker ps -a confirms the container is healthy:
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
a13044ba9513 self-hosted-streamlit-prod "/usr/bin/supervisor…" 2 minutes ago Up 2 minutes (healthy) 0.0.0.0:80->80/tcp streamlit-prod
And inspecting the logs with cat /var/log/healthcheck.log inside the container produces:
2025-01-18 14:13:57,833 - healthcheck.py - INFO - [CHECK] Starting health check
2025-01-18 14:13:58,068 - healthcheck.py - INFO - app_1 - RUNNING - pid 8, uptime 0:00:03
2025-01-18 14:13:58,068 - healthcheck.py - INFO - app_2 - RUNNING - pid 9, uptime 0:00:03
2025-01-18 14:13:58,068 - healthcheck.py - INFO - nginx - RUNNING - pid 10, uptime 0:00:03
2025-01-18 14:13:58,077 - healthcheck.py - INFO - [CHECK] http://localhost:80/app-1 is online
2025-01-18 14:13:58,078 - healthcheck.py - INFO - [CHECK] All systems are GO!
Feeling accomplished: 🎉🥳🎉🥳🎉🥳🎉🥳🎉
☁ Setting Up Cloudflare Tunneling for Easy SSL
I won’t dive too deep into this section since Cloudflare provides an excellent tutorial on the subject.
For installation, I chose to download the latest release directly from the source:
RUN curl -L https://github.com/cloudflare/cloudflared/releases/latest/download/cloudflared-linux-amd64 -o /usr/local/bin/cloudflared && \
chmod +x /usr/local/bin/cloudflared
RUN mkdir -p /var/log/supervisor /etc/cloudflared
COPY cloudflare/ /etc/cloudflared/
Next, I added the following Supervisor program configuration for Cloudflare:
[program:cloudflared]
command=/usr/local/bin/cloudflared tunnel run dash
autostart=true
autorestart=true
stderr_logfile=/var/log/supervisor/cloudflared.err.log
stdout_logfile=/var/log/supervisor/cloudflared.out.log
🚀 Deployment
Let’s be honest—the cloud can be a daunting and expensive place. Instead of deploying to AWS, I repurposed an old laptop, cloned the repository, ran the Makefiles, and deployed it locally.
Feel free to check it out! Just a heads-up: I might accidentally kill the process at some point.
Here are the links:
🤔 Conclusion
I’m still refining the code, but if you want to see what the repository looked like at the time of writing this blog, you can find it here.
I have a few ideas brewing for the next blog post, so stay tuned!
Let me know what you think!